NLG with GPT-2
When GPT-3 was released, people were amazed by its ability to generate coherent, natural-sounding text. In fact, it wasn’t just text; it could generate JavaScript code, write code documentations and docstrings, as well a host of other language generation tasks. More recently, OpenAI revealed DALL·E, which is essentially GPT-3 trained on images. When prompted a textual description, the model can actually generate images that match the provided description. It’s so fascinating, yet at the same time somewhat discomforting to see how good it is.
GPT-3 was not released publicly over ethics and security concerns. So instead, we will be using GPT-2, its smaller predecessor, to see how one can go about natural language generation. Note that GPT models essentially share the same underlying architecture. The only difference is that the more recent GPT models are huge; GPT-3, for instance, has 175 billion parameters.
This post will be a combination of a few things. Namely, we will explore not only how to use the HuggingFace transformers library at a basic level for NLG, but we will also look at various generation and sampling methods that can be employed to make generated sentences sound more natural. In writing this tutorial, I heavily referenced the HuggingFace transformers documentation as well as this HuggingFace blog post on language generation.
Without further ado, let’s get started!
Setup
First, we need to download and install the transformers library. I’m running this notebook on Google Colab. While Colab ships with many libraries by default, such as PyTorch, TensorFlow, NumPy, and other basic data science tools, it does not come with transformers.
!pip install transformers --quiet
[K |████████████████████████████████| 1.8MB 10.0MB/s
[K |████████████████████████████████| 2.9MB 41.9MB/s
[K |████████████████████████████████| 890kB 46.0MB/s
[?25h Building wheel for sacremoses (setup.py) ... [?25l[?25hdone
Next, we need to download the GPT-2 model and tokenizer. For open-end generation, HuggingFace will set the padding token ID to be equal to the end-of-sentence token ID, so let’s configure that manually beforehand as well.
from transformers import GPT2TokenizerFast, GPT2LMHeadModel
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
# Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
Before we jump into using these models and tokenizations, let’s take a deeper look into GPT’s tokenization and encoding scheme.
Tokenization
GPT-2 uses byte-pair encoding, or BPE for short. BPE is a way of splitting up words to apply tokenization.
Byte Pair Encoding
The motivation for BPE is that
- Word-level embeddings cannot handle rare words elegantly (
<UNK>) - Character-level embeddings are ineffective since characters do not really hold semantic mass
If we think about it, the real meaning of words come from units that are larger than characters, but smaller than words. For example, the word “bigger” is really a combination of “big” and the comparative “-er”. From this admittedly simplified example, one might deduce that we should create embeddings for these intermediate units that lie between characters and words. Hence BPE, or other variant tokenization methods such as word-piece embeddings used in BERT, employ clever techniques to be able to split up words into such reasonable units of meaning.
BPE actually originates from an old compression algorithm introduced by Philip Gage. The original BPE algorithm can be visually illustrated as follows. The GIF was taken from Akashdeep Jaswal’s Medium article.

As you can see, the algorithm interatively tries to find repeated n-grams (in this case, bi-grams) and replaces them with another token. If we turn this process iteratively, we ultimately end up with an encoded sequence that is much shorter than the original. This compression is also lossless since we can reverse this process to obtain the exact original sequence, as long as we properly cache or store the intermediery encoding representations used to substitute recurring bi-grams.
BPE in the context of NLP and tokenization uses a similar technique, but is slightly different in that we don’t compress the original sequence via substitution; instead, recurring bi-grams are merged into a single token (a uni-gram). Jaswal’s article I linked above has some executable code snippets that demonstrate how these work, but for simplicity’s sake I’ll opt to explain how this works in plain language.
Let’s say we have the following corpus:
corpus = 'low lower newest wildest'
We can then apply some simple preprocessing and basic tokenization to form
vocab = {
'l o w </w>',
'l o w e r </w>',
'n e w e s t </w>',
'w i d e s t </w>',
}
Then, we count the number of character pair occurences. For instance, we might observe that 'es' occurs twice, whereas others occur only once. Thus, we can consider this most commonly occurring pair as a new unit, a single token, and repeat the process of merging characters into single tokens.
vocab = {
'l o w </w>',
'l o w e r </w>',
'n e w es t </w>',
'w i d es t </w>',
}
We can now mege 'es' with 't', as the bi-gram seems to be fairly common.
vocab = {
'l o w </w>',
'l o w e r </w>',
'n e w est </w>',
'w i d est </w>',
}
In theory, if we repeat this process with a huge corpus for a set amount of iterations—which is a hyperparameter we can control—we would end up with reasonable units that occur most frequently. The idea is that these combinations of character sequences that occur more frequently should encode some meaning, similar to what we saw with “-er” in the “bigger” example.
HuggingFace Tokenizers
Now that we have a basic idea of what BPE tokenization is, we can now dive into the long-awaited hands-on portion of this post. Using the tokenizer that we initialized earlier, let’s try encoding a simple sentence. Since we will be using PyTorch, we can tell tokenizer to output a PyTorch tensor instead of vanilla Python lists by specifying return_tensors="pt". (If you are using TensorFlow, simply replace the argument with return_tensors="tf".)
input_ids = tokenizer.encode("I enjoy walking with my cute dog", return_tensors="pt")
input_ids
tensor([[ 40, 2883, 6155, 351, 616, 13779, 3290]])
Because the library assumes batches by default, we get a tensor with an additional batch dimension.
Let’s get a more detailed look at what tokenizers do. First, let’s try converting the input IDs back into their original tokens.
tokenizer.convert_ids_to_tokens(input_ids[0])
['I', 'Ġenjoy', 'Ġwalking', 'Ġwith', 'Ġmy', 'Ġcute', 'Ġdog']
Not only can we see that the original sentence is now tokenized into words, we also see that each token is prepended with what appears to be a special character.
We can in fact achieve the same result by calling the tokenize method.
tokenizer.tokenize("I enjoy walking with my cute dog")
['I', 'Ġenjoy', 'Ġwalking', 'Ġwith', 'Ġmy', 'Ġcute', 'Ġdog']
By converting these tokens to IDs, we can essentially do exactly what the .encode() function achieved for us.
tokenizer.convert_tokens_to_ids(tokenizer.tokenize("I enjoy walking with my cute dog"))
[40, 2883, 6155, 351, 616, 13779, 3290]
Another common way to use tokenizers is to invoke __call__() itself, which can be done by passing in the original sentence into the tokenizer and treating it as if it’s a function.
tokenizer("I enjoy walking with my cute dog")
{'input_ids': [40, 2883, 6155, 351, 616, 13779, 3290], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
Note that we can batchify things by passing in a list of sentences.
tokenizer(
["I enjoy walking with my cute dog", "This is another dummy sentence"]
)
{'input_ids': [[40, 2883, 6155, 351, 616, 13779, 3290], [1212, 318, 1194, 31548, 6827]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1]]}
But the problem with this approach is that we can’t use these sentences as they currently are. To batch things, we need to add padding. This is where the attention mask in the dictionary becomes important: if you recall the earlier post on transformers, attention masks are used in two cases:
- Hide padding tokens from self-attention
- Hide tokens beyond the current timestep from the decoder (look ahead)
In this case, since we are concerned with batching, the attention mask will be applied to the shorter sequence so that padding can be added to properly batch the two inputs.
tokenizer.pad_token = tokenizer.eos_token
tokenized = tokenizer(
["I enjoy walking with my cute dog", "This is a sentence"],
padding=True
)
for key, value in tokenized.items():
print(key, value)
input_ids [[40, 2883, 6155, 351, 616, 13779, 3290], [1212, 318, 257, 6827, 50256, 50256, 50256]]
attention_mask [[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 0, 0, 0]]
As can be seen, the shorter sentence is padded with padding tokens, which in this case, has been set as the end-of-sentence tokens, the index of which is 50256. The attention mask also contains zeros to accomodate for the padding behavior.
Now that we have a fairly good understanding of how tokenization works with GPT-2 and more generally the HuggingFace transformers library, let’s get started with the fun part: natural language generation with GPT-2!
Generation
Mathematically, an auto-regressive language model $\theta$ can be expressed as
\[P(w_{1:T} \vert \theta) = \prod_{t = 1}^T P(w_t \vert w_{1:t - 1}, \theta)\]In other words, language models seek to maximize the likelihood of seeing some sentence by considering the product of conditional probabilities up to the point of generation.
Greedy Generation
The first most obvious way of performing NLG using a auto-regressive LM like GPT-2 is to use greedy search. A language model can be constructed as a tree, as shown below:
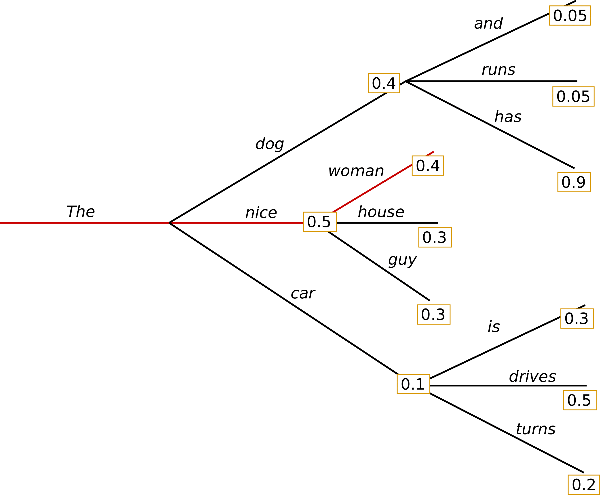
Each branch represents a probability, and we can compute conditional probabilites simply by multiplying each value associated with the current edge we are on. For example, the probability of seeing the opening phrase “The nice woman” can be decomposed into
\[\begin{align} P(\text{The nice woman}) &= P(\text{The}) \cdot P(\text{nice} \vert \text{The}) \cdot P(\text{woman} \vert \text{The nice}) \\ &= 1 \cdot 0.5 \cdot 0.4 \\ &= 0.2 \end{align}\]Here, we assumed that “The” was given to the model as the opening word; hence the probability of 1.
As the name implies, greedy generation is a simple alogrithm in which we simply select the edge with the highest conditional probability associated with it at each time step, and repeat this process iteratively until we reach the end-of-sentence token or until we reach the maximum time step specified by the user. In the example above, the red line represents the greedy path.
Let’s try this out with GPT-2. To use greedy generation, we simply call .generate() on the model with the input IDs. The input IDs serve as the opening phrase that will give the model a starting point to anchor on. Then, we decode the generated output so that it can be presented in human-readable format instead of some cryptic token indices.
greedy_output = model.generate(input_ids, max_length=50)
tokenizer.decode(greedy_output[0], skip_special_tokens=True)
"I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.\n\nI'm not sure if I'll"
While the output is grammatically sound, it’s not coherent at all. The model repeats phrases over and over, and even the repeated phrase seems to contradict the starting phrase.
Beam Search
One way to remedy this problem is beam search. While the greedy algorithm is intuitive conceptually, it has one major problem: the greedy solution to tree traversal may not give us the optimal path, or the sequence that which maximizes the final probability. For example, take a look at the solid red line path that is shown below.
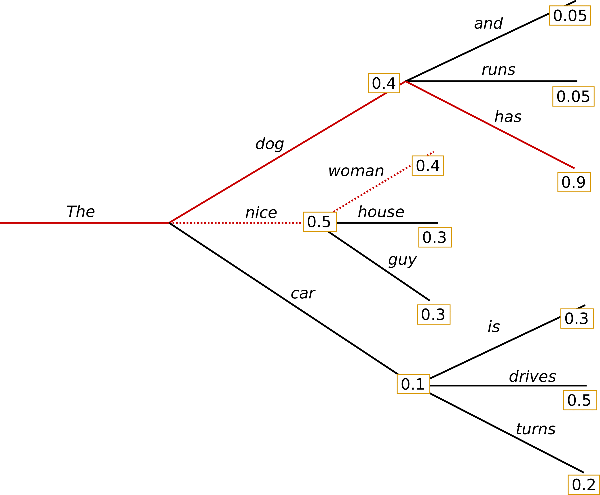
We can easily calculate the probability of this path, which turns out to be 0.36. This value is larger than the previous probability we calculated for the greedy output, “The nice woman.” In short, taking the greedy solution at each time step does not necessarily mean that we will end up with the most natural-sounding generated sentence.
Beam search remedies this problem and seeks to identify the path with the highest probability by maintaining a number of “beams,” or candidate paths, then selecting the beam that has the highest final probability. Think of this as having a number of workers who each venture down different paths. At the end, we tally the final probability that each worker produced, then return the optimal path found by the worker with the highest end probability. In the illustration, the number of beams is set to two, which is why there is the greedy path we found earlier, as well as another alternative path that results in “The dog has,” a phrase that ends up being more probable than the greedy output. With this understanding, we can now view the greedy approach as having just one beam.
In HuggingFace transformers, we can easily conduct beam search by specifyinng the number of beams parameter. Let’s see what we get if we have 50 beams.
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
tokenizer.decode(beam_output[0], skip_special_tokens=True)
"I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.\n\nI'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll"
Well, the model added line breaks, but for the most part, it does not seem to have solved the repetition problem. Beam search certainly helps diversify things, but it does not fundamentally engage with the fact that we are seeing the same exact phrase over and over in the generated sequence.
N-gram Penalty
A more direct solution to this problem would be to configure an n-gram penalty. Conceptually, n-gram penalty ensures that no n-gram appears twice by setting the probability of selecting a word that would otherwise create repeated n-grams be zero. Put differently, next word candidates that can produce repeated n-grams are removed from the list to selectable edges from the tree.
Let’s see this in action.
beam_output_no_repeat = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
tokenizer.decode(beam_output_no_repeat[0], skip_special_tokens=True)
"I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.\n\nI've been thinking about this for a while now, and I think it's time for me to take a break"
This output is the most natural-sounding sequence we have generated with the model so far! This result tells us that correctly generation methods are very important when generating sequences with language models like GPT-2.
Multiple Generation
On a quick side note, it is probably worth mentioning that we can also use beam search to sample a bunch of different probable sequences. Instead of simply having beam search return the most likely sequence, we can make it return the top $K$ sequences as shown below.
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
for i, output in enumerate(beam_outputs):
decoded = tokenizer.decode(output)
print(f"{i}: {decoded}...\n")
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break...
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to get back to...
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to take a break...
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to get back to...
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a step...
The beams all produce similar results, but it’s also interesting to see how the minute changes that can be observed across the different beams are all probable configurations that could occur in real-life text.
Random Sampling
HuggingFace transformers offers even more functionality, however. Namely, we can avoid the greedy, deterministic paradigm altogether and apply random sampling. This way, even words with low conditional probabilities attached to them could be selected, especially if the length of the sequence gets longer. While this may sound like a bad idea, there is good reason to add elements of randomness to NLG: sentences produced by beam search are often too predictable and bland when compared to actual sentences that humans write and speak.

In the transformers API, this is merely a matter of adding an additional argument, do_sample=True.
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
tokenizer.decode(sample_output[0], skip_special_tokens=True)
'I enjoy walking with my cute dog," said Ms Brandon Harris, 45, from the 7000 block of Columbus Avenue south of Mt. Circle in Concord Village, according to an online social media post.\n\nShe also wrote to customers able to visit the'
Now we see a lot more noise in the output data. As a whole, the text is a little more chaotic and unpredictable, to the point that some of it appears to be irrelevant rambles. What we need to do is to keep this noise to a reasonable degree so that we can generate interesting sequences that aren’t always too predictable.
Softmax Temperature
To prevent the model from selecting tokens that are too unlikely, we can control the softmax temperature. We’ve seen this notion of softmax temperature many times, most recently in the post on knowledge distillation. Namely, by setting the temperature, we can make the distribution get sharper; in other words, highlight larger values and de-emphasize smaller ones.
sample_output_temperature = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
tokenizer.decode(sample_output_temperature[0], skip_special_tokens=True)
'I enjoy walking with my cute dog and talking to him, listening to him and talking with him at the gym," she said, when asked about her desire to have the best life possible for her dog.\n\n"I enjoy the interaction, but'
An interesting way of understanding temperature is that, when the softmax temperature is set to 0, we end up with greedy sampling, since 0 temperature would essentially overshadow all other probabilities except the largest one.
Top-K Sampling
Another popular way of denoising the output is using top $K$ sampling. The idea is that we want to consider only the top $K$ most likely tokens at any give time step instead of considering all possible options in the model’s vocabulary. We then redistribute the probability mass of these top $K$ possible options (you could view this as normalizing the $K$-way distribution)and perform sampling on that new sliced distribution. Through this process, we can effectively force the model to only focus on the top $K$ most likely options, thus preventing it from producing sequences that are too random.
sample_output_top_k = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
)
tokenizer.decode(sample_output_top_k[0], skip_special_tokens=True)
"I enjoy walking with my cute dog [in Boston], but after I did the Boston Marathon this past weekend, I made a big surprise trip to Boston to try out for me the first time when I was a kid: It's the New England Derby"
Well, I would say the result is still somewhat random and incoherent. So there’s more to be done.
Top-P Sampling
An improvement over top $K$ sampling is top $P$ sampling. Instead of having a fixed number $K$ at each time step, in top-$P$ sampling, we choose words up to the point that the running cumulative probability does not exceed the threshold. In other words, we construct the smallest set possible such that
\[W = \{w_1, w_2, \cdots, w_n\}, \\ \sum_{w \in W} P(w \vert w_{1:t - 1}) \leq p\]In the notation above, we selection the top $n$ most likely tokens such that the sum of the probabilites of taking those $n$ nodes does not exceed the pre-set probability threshold. Of course, the standard drill also applies: we need to normalize the selected distribution, since the probabilities won’t add up to 1; it will most likey add up to a number that is very close to, but slightly smaller than, the probability threshold.
sample_output_top_p = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
tokenizer.decode(sample_output_top_p[0], skip_special_tokens=True)
"I enjoy walking with my cute dog. Any small interaction is wonderful and I can't wait to find out what people would do with their favorite dog!\n\n--Dave-"
We don’t know what is going on there at the very end with Dave, but overall the sentence not only flows well, but it is also reasonably coherent. The generated sequence also can maintain coherence over long ranges, as we see that the dog theme flows throughout the entire sequence from start to end. NLG is definitely something that transformer models can do well, and this example is a testament to that statement.
Conclusion
In this post, we got a taste of what natural language generation is like with GPT-2. The HuggingFace transformers library is an excellent way to get started with NLG or really any NLP-related task, as it provides a wealth of models to choose from, all with pretrained weights that can be used in an off-the-shelf manner. I used BERT-variants for auto-tagging my blog post articles, and it has been working very well to my satisfaction. Perhaps I could integrate GPT-2 into the current workflow by using it to generate good, concise titles. Just food for future thought.
I hope you enjoyed reading this post. Catch you up in the next one!