Last week, I had the pleasure of joining the first ever virtual Scikit-learn sprint, kindly organized by Reshama Shaikh of Data Umbrella and NYC PyLadies. Although it was just a four-hour sprint held entirely online, it was a fantastic learning experience that helped me better understand collaborative workflow and the joy of contributing to open source.
Had a great time yesterday contributing to @scikit_learn as part of the #ScikitLearnSprint organized by @DataUmbrella and @NYCPyLadies. Thank you so much to all the organizers and core developers for arranging this event! #OpenSource
— Jake Tae (@jaesungtae) June 7, 2020
A salient feature of the Scikit-learn sprint is pair programming, where participants are grouped into teams consisting of two people. Each pair works as a team to address open issues, report new issues, or submit pull requests. When I first learned about pair programming through the sprint, I thought it was a great idea since these pairs could be arranged in such a way that participants with relatively little experience (like myself) could be paired up with more experienced developers to tackle complicated issues that they otherwise would not have been able to.
On the day of the sprint, I almost didn’t have a partner because they didn’t show up. Fortunately, however, thanks to the support from the organizing team (shoutout to Noemi), I was quickly matched up with another participant. Together, my newfound partner and I worked on a total of 1.5 issues for a duration of about two hours. I say 1.5 because we successfully pushed out a pull request (which has now been merged!) and another draft PR in progress that was eventually closed due to the impossibility of retrieving word columns for the rcv1 Reuters news dataset. Another minor PR I submitted a few days prior to the sprint also got merged. Although the issues addressed were minor in significance, it was still a highly rewarding experience nonetheless. Contributing to open source has an oddly addicting nature to it—once a docs improvement PR is merged, you find yourself scrolling through GitHub, trying to find issues relating to API improvements or feature requests that seem interesting, yet also doable by your standards.
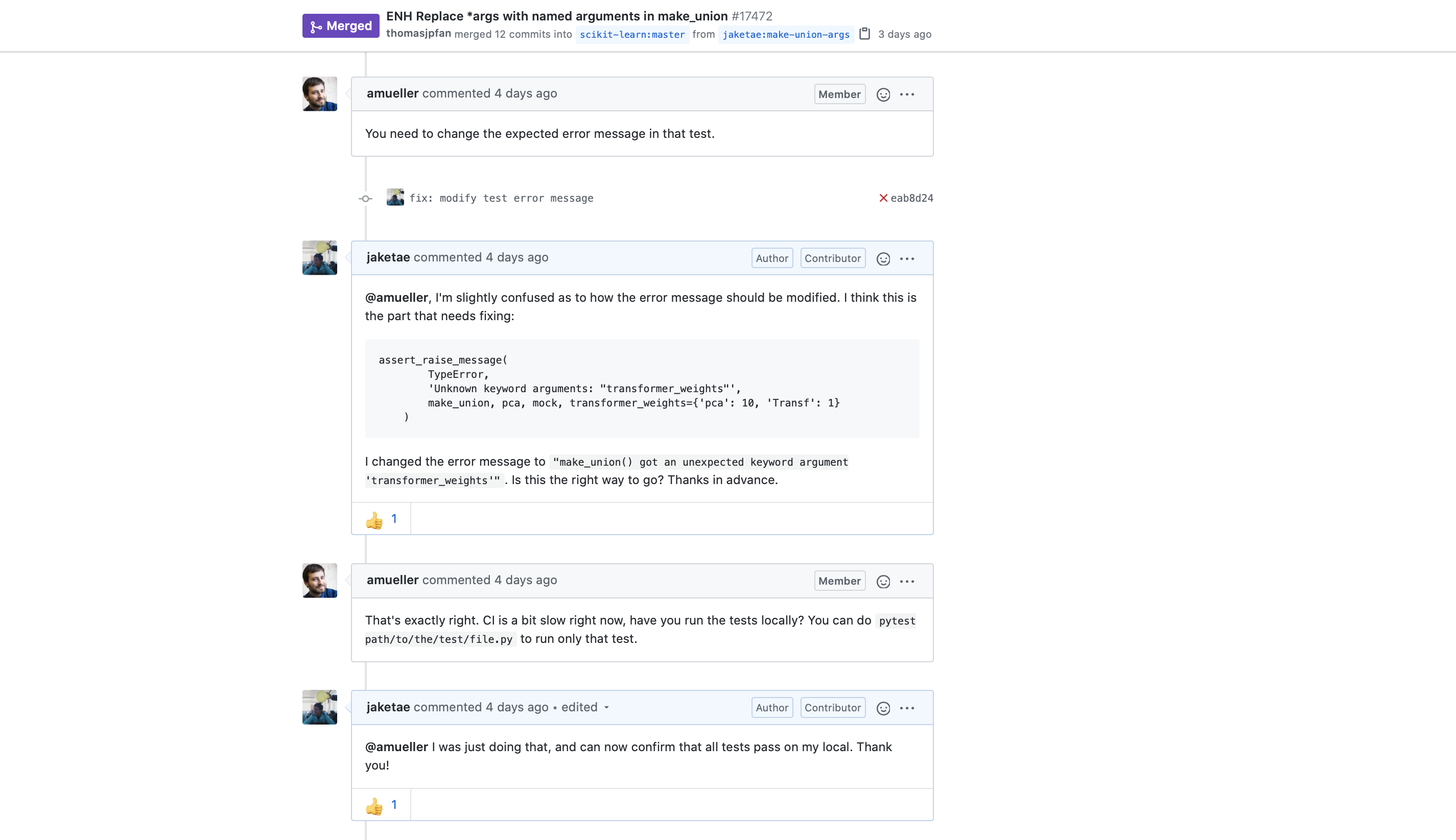
Of course, not everything in the sprint panned out nicely for our team. For one, the sprint started at 1 in the morning in Korean Standard Time, so I wasn’t sure if I would be able to stay up until 5AM. I ended up finishing a bit short a little past 4. My partner also decided to leave early on their end, so thankfully things worked out.
Besides the inevitable (and entirely anticipated) timezone issue, my partner and I also struggled to set up our workflow on GitHub. My initial thought was that one of us would have to add the other as a collaborator on a forked repository. A few moments later, however, I was misguided by another idea, that perhaps we could fetch from a PR; for instance, my partner could open a PR, and I would fetch from that PR, make modification on my local, then push it up back to remote. It turned out that this was the wrong approach; pushing from my local wouldn’t update the PR since tracking doesn’t quite work that way. In the end, we resorted back to our initial plan of collaborating on a branch in a forked repository. Hopefully, things worked out well from then on.
Despite it being entirely virtual, the Scikit-learn sprint was organized extremely well. Discord was the main channel of communication, as well as Zoom for an introductory orientation prior to the actual sprint. Beginner-friendly videos on how to contribute to Scikit-learn (or any open source repository in general) were posted on the Data Umbrella website to help newcomers get started. On top of all that, organizers and core developers also provided continuous assistance to participants with various aspects of the sprint—our team, in particular, received helpful guidance with Git as we were setting up our workflow as described earlier. I also saw others receive help with creating local builds or setting up virtual environments. They also provided prompt feedback on opened PRs, kindly pointing out which test had failed for what reason, and how one might navigate the problem.
Although I had contributed to open source before, this was my first time working together with a partner. In retrospect, this collaborative nature is what made the sprint all the more enjoyable and productive. The numbers speak for themselves: in total, sprint participants submitted more than 50 PRs, half of which have already been merged, and the rest still in progress:
Some stats on today's ONLINE @DataUmbrella #ScikitLearnSprint:
— Reshama Shaikh (@reshamas) June 6, 2020
• 27 PRs MERGED!
• 27 PRs still *open* (TBC) (⚖️)
• 42 new & returning contributors
• 13 helpers
• ➕➕❤️ the contributors emojis!
Thanks to all for spending this Saturday across 16 different time zones with us! pic.twitter.com/MhrjtkMsui
The sprint also introduced me to other helpful coding practices, such as unit testing and linting—I had been using black for auto-formatting, but exposure to flake8 was certainly helpful. I’ll also shamelessly stick in here the fact that it was simply great interacting with Scikit-learn’s core developers like Andreas Mueller, whom I had only seen on video lectures and ML-related articles. And of course, do I even have to mention the fact that Scikit-learn is objectively the coolest ML package there is in Python?
Thanks again to Data Umbrella and NYC PyLadies for organizing this sprint!